Python Use Continue to Remove Duplicates
Overview
Duplicates present in Python lists can be removed using various methods depending upon the type of elements present in the list, the size of the list, whether the order of the elements should be preserved or not, and the efficiency of the removal approach. These methods can be iterative, use built-in functions for implementation, or import modules for their functionality.
Scope of Article
- This article provides an in-depth review of various methods that can be used to remove duplicates from a list in Python.
- The article describes the different methods and their implementation using the Python programming language.
Introduction
Suppose you got a job offer from an organization, and before joining it, you wish to explore workforce diversity. After doing a lot of research, you got a database of employees with their first and last names and their nationality.
Now, the best approach to explore workforce diversity is to store the nationality of the employees in a list and remove all the duplicate entries as described below:
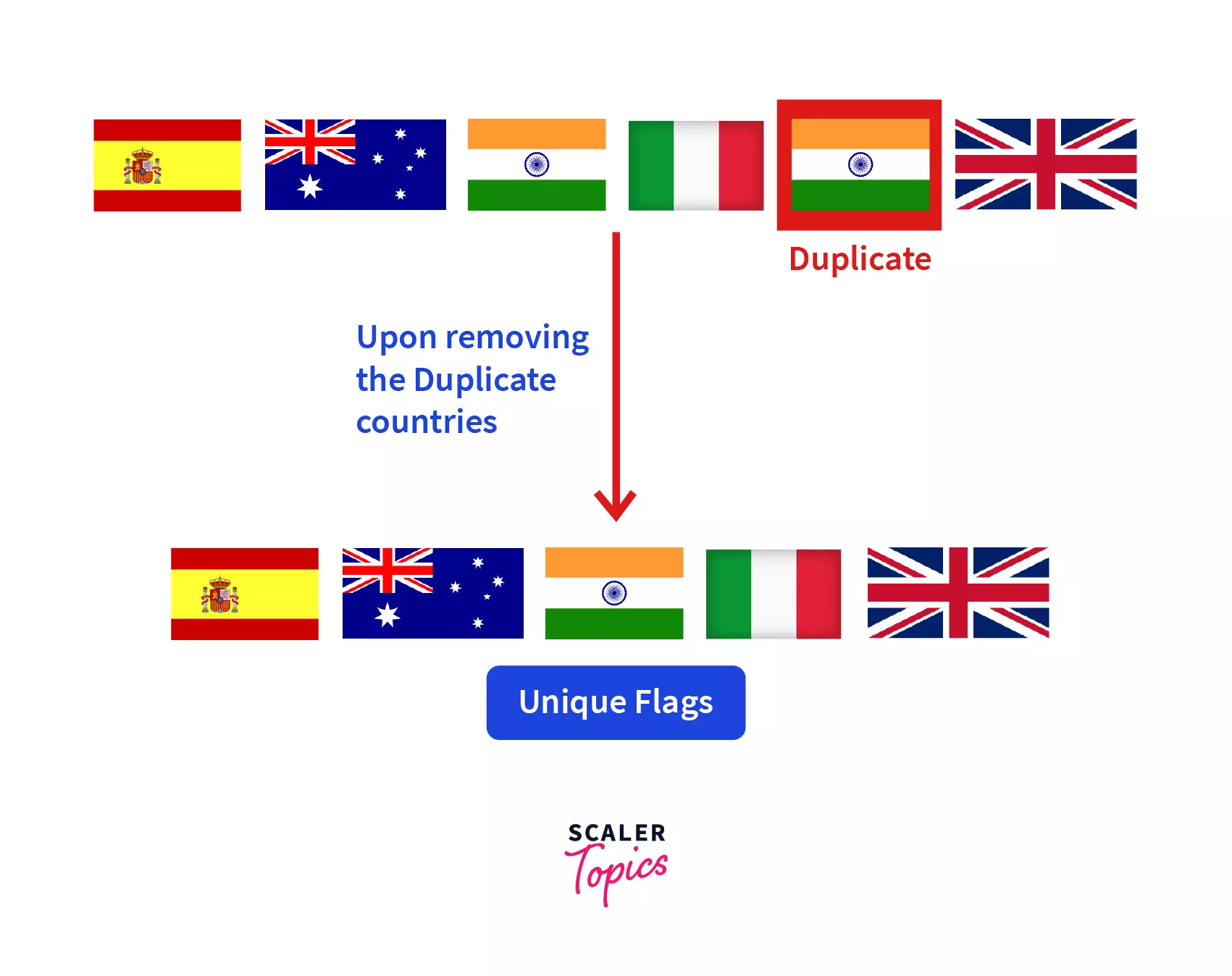
As you can notice in the above example, the removal of the duplicates process comes in handy to explore the diversity of the employees of an organization.
In this article, we will explore the numerous ways to delete duplicate values from a list in Python.
Example: Remove any Duplicates from the List in Python
To better understand all the different methods of removing duplicates from a list, let's consider an example having an integer list a that contains 20 numbers, as shown below:
# Example List a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ]
Here, after removing all the duplicates from the list; we will be left with a list containing ten unique/distinct elements:
# Unique List unique_list = [ 10 , 20 , 30 , 80 , 40 , 100 , 50 , 60 , 70 , 90 ]
Now, let's explore various methods to achieve the above result.

Method 1: Naive Method (Iterative or Temporary Method)
The basic approach to removing duplicates from a list in Python is to iterate through the elements of the list and store the first occurrence of an element in a temporary list while ignoring any other occurrence of that particular element.
In the naive method, the basic approach is implemented by:
- Traversing the list using for-loop.
- Adding the elements to a temporary list if it is not already present in it.
- Assigning the temporary list to the main list.
Now, let's look at the implementation of the Naive Method:
Code:
# main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # empty temporary list temp = [] # removing duplicates via Naive Method for element in a: if (element not in temp): temp.append(element) # Assigning the temporary list to the main list a = temp print ( "Unique List : " , a)
Output:
Unique List : [ 10 , 20 , 30 , 80 , 40 , 100 , 50 , 60 , 70 , 90 ]
As we can observe from the code, the naive method uses the in keyword to check whether an element is already present in the temporary list or not. Thereby storing only the unique elements in the temporary list.
In this method, we are creating a temporary list to store unique elements. Hence, the naive method requires extra space while removing duplicates from the list.
Highlights:
(1) The main list is traversed, and unique elements are added to a temporary list.
(2) The in keyword is used to determine the first occurrence of the elements.
(3) It requires extra space to store unique elements.
Method 2: Using List Comprehension
Instead of using the For-loop to implement the Naive method of duplicates removal from the list, we can use Python's List comprehension functionality to implement the Naive method in only one line of code.
Now, let's look at the implementation of the Naive Method using List comprehension:
# main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # empty temporary list temp = [] # removing duplicates via List comprehension [temp.append(element) for element in a if element not in temp] print ( "Unique List : " , temp)
Output:
Unique List : [ 10 , 20 , 30 , 80 , 40 , 100 , 50 , 60 , 70 , 90 ]
Here, we initialize a temp variable to store the unique elements. Then, we use list comprehension to extract the unique elements from the input list. Hence, similar to the naive method, we require extra space to store the unique elements in a temp variable.
Let's take a look at the list comprehension statement from the above example: [temp.append(element) for element in a if element not in temp] Here, this statement indicates that :
- A for loop will iterate over the input list a and extract elements that are not present in the temp list with the help of the if condition.
- The extracted elements will be added to the temp list with the help of the List's built-in append(element) function.
NOTE:
List comprehension is a functionality of Python that is used to create new sequences from other iterables like tuples, strings, lists, etc. It shortens the code and makes it easier to read and maintain.
Syntax: [expression for item in iterable if condition]
Example: a = [x for x in range(10) if x >5] Here, a : [6,7,8,9]
Highlights:
(1) One-liner shorthand of the Naive Method.
(2) The code is easier to read and maintain.
Method 3 : Using List Comprehension + enumerate()
While using the List comprehension method, we find the distinct elements and store them in a temporary list. Whereas, when we use the List comprehension along with enumerate() function, the program checks for already occurred elements and skips adding them to the temporary list.
Enumerate function takes an iterable as an argument and returns it as an enumerating object (index, element), i.e., it adds a counter to each element of the iterable.
Now, let's look at the implementation of the List comprehension + enumerate() method:
Code:
# main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # empty temporary list temp = [] # removing duplicates via List comprehension + enumerate() temp = [element for index, element in enumerate (a) if element not in a[:index]] print ( "Unique List : " , temp)
Output:
Unique List : [ 10 , 20 , 30 , 80 , 40 , 100 , 50 , 60 , 70 , 90 ]
Here, a[:index] is used to access already occurred elements.
Here, the list comprehension statement can be re-written as:
for index, element in enumerate (a): if (element not in a[:index]): temp.append(element)
Here, we can notice that:
- The for loop is accessing every element from the input list along with its index (as provided by enumerate function).
- We are checking whether the particular element is present in the already accessed elements list, i.e., in the list a[ : index].
- For example, for the second element, i.e., the element having an index equal to 1, the if condition will check whether that element is present in the list a[ : 1] i.e., it is the same as the first element or not. If not, then it is unique and is stored in the temp variable.
Highlights:
(1) Similar to the List comprehension method.
(2) It checks for already occurred elements and skips adding them.
Method 4 : Using list.count() + list.remove()
Duplicates in the list can also be removed with the help of Python List's in-built functions such as count() and remove():
- list.count(element) - Returns the number of occurrences of an element in the list.
- list.remove(element) - Removes the first occurrence of an element from the list.
Let's understand the count() + remove() method with the help of an example:
Code:
# main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # removing duplicates via list.count() + list.remove() method for element in a[:]: if (a.count(element) > 1 ): a.remove(element) print ( "Unique List : " , a)
Output:
Unique List : [ 20 , 30 , 100 , 50 , 70 , 80 , 40 , 60 , 90 , 10 ]
Here, a copy (a[:]) of the main list is traversed, and the occurrence of each element is calculated with the help of the count() function. If the element is repeated, i.e. its count > 1, then it is removed from the main list (Modifies the main list in-place) with the help of the remove() function.
NOTE:
- Because of the in-place element removal functionality of the remove() function, this method is better than the naive method as it requires no extra space to store the unique elements.
- Here, we are using a copy of the main loop because removing an element from the same iterator (same list) can lead to unwanted results.
Highlights:
(1) In-place removal of duplicate elements.
(2) Uses the in-built functions list.count(element) and list.remove(element).
Method 5: Set Method
All the methods that we have discussed so far are very simple to understand and implement. But, they are not very efficient when working with a list having a large number of items. To overcome this issue, we can use the Set data structure of Python.
By definition, Sets cannot contain duplicate elements. Hence, by converting a list having duplicate elements to a set, we can easily remove duplicate items from the list and create a new list from an unordered Set. This new list will have unique elements.
Let's understand the Set method with the help of an example:
Code:
# main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # removing duplicates via Set method temp = list ( set (a)) print ( "Unique List : " , temp)
Output:
Unique List : [ 100 , 70 , 40 , 10 , 80 , 50 , 20 , 90 , 60 , 30 ]
Here, the main drawback of this method is that the original List order is not maintained as we are creating a new list from an unordered set.
Highlights:
(1) Most Popular, Simple, and Fast method suitable for a list of any size.
(2) Uses Python's Set data structure.
(3) Drawback - Order is not preserved in this method.
Method 6 : Set + sort() Function Method
In some cases, we may need to remove duplicates while maintaining the order of elements of the list. In this situation, we can use the Set method and the sort() function to preserve the order while using the Set's functionality.
Let's look at an example to understand this concept:
Code:
# main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # removing duplicates via Set + sort() method temp = list ( set (a)) # sorting the new list taking the input list's index as the key function temp.sort(key=a.index) print ( "Unique List : " , temp)
Output:
Unique List : [ 10 , 20 , 30 , 80 , 40 , 100 , 50 , 60 , 70 , 90 ]
Here, the sort() function sorts the temp list in-place by making comparisons based on the key function provided as an argument. Here, the main list's index is provided as the key function that helps to preserve the order as the elements are sorted according to the order of their occurrence in the main list a.
NOTE:
Because of the addition of the sorting function, this method is slower than the Set Method.
Highlights:
(1) Set method coupled with the sort() function preserves the Order.
(2) Slower than the Set Method.
Method 7 : The collections.OrderedDict.fromkeys() Function
Another way of removing duplicates from a list is by using the OrderedDict object provided by the collections module. Ordered Dict is a dictionary that remembers the order in which the keys of the dictionary are inserted. We can use the OrderedDict object to remove duplicates from a list by following these steps:
- Convert the main list to an OrderedDict object (a special type of dictionary that remembers the order in which the keys were first inserted) by providing the values of the list as keys of the dictionary. It is achieved using OrderedDict.fromkeys() function.
- Now, since the dictionary keys are unique and the insertion order (the order in which the elements were inserted in the dictionary) is maintained in OrderedDict, we get a dictionary whose keys represent the unique elements from the main list.
- Convert this dictionary to list using list() function.
Let's look at an example to understand the OrderedDict Method:
Code:
# importing OrderedDict from the collections module from collections import OrderedDict # main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # removing duplicates via the OrderedDict method temp = list (OrderedDict.fromkeys(a)) print ( "Unique List : " , temp)
Output:
Unique List : [ 10 , 20 , 30 , 80 , 40 , 100 , 50 , 60 , 70 , 90 ]
NOTE:
From Python 3.7 onwards, the built-in Python Dictionary is guaranteed to maintain the insertion order. Hence, we can use the normal dict.from_keys() function to achieve the same result as that described in the OrderedDict method.
Highlights:
(1) Uses OrderedDict object provided by the collections module.
(2) Converts the list to an OrderedDict, considering the list elements as dictionary keys.
(3) Fastest Method to remove duplicates while preserving the order.
Method 8 : Numpy unique() Function
Duplicates in the list can also be removed with the help of the unique() function provided by the Numpy module:
- unique(a) - It returns a sorted numpy array of unique elements. It converts the list into a numpy array and removes the duplicates, and finally sorts the list.
Syntax- numpy.unique(sequence)
Now, let's look at an example to understand the Numpy unique() function:
Code:
# importing Numpy module import numpy as np # main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # removing duplicates via unique() function temp = np.unique(a).tolist() print ( "Unique List : " , temp)
Output:
Unique List : [ 10 , 20 , 30 , 40 , 50 , 60 , 70 , 80 , 90 , 100 ]
Here, the tolist() function converts the returned Numpy array to a Python list.
In the above example, we are importing the numpy module and giving it the name (alias), i.e., np for further reference in the program.
Now, to use the unique(seq) function of the numpy library, we are using the dot operator (.) to access the function and then converting its returned value to a list using tolist() function. Thereby, getting a list having unique elements.
Highlights:
(1) Numpy module provides a unique() function using which we can delete duplicates from a list.
(2) unique() function return a sorted list of unique elements. Hence, the order is not preserved.
Method 9: Pandas Methods
Duplicates in the list can also be removed with the help of the functions provided by the Pandas module:
- unique(a) - It returns a numpy array containing unique elements in order of their appearance from the input list. It uses Hashing for its implementation and doesn't require any sorting. Hence it is faster than Numpy's unique() function.
- Series.drop_duplicates() - This function works on Pandas Series, and it is used to get Pandas series with duplicate values removed. Hence, to use this function to remove duplicates from a list, we first have to convert the list to Pandas Series.
Now, let's look at an example to understand the Pandas module functions to remove duplicates:
Code:
# importing Pandas module import pandas as pd # main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # removing duplicates via unique() function temp_1 = pd.unique(a).tolist() print ( "Unique List 1 : " , temp_1) # removing duplicates via drop_duplicates() function temp_2 = pd.Series(a).drop_duplicates().tolist() print ( "Unique List 2 : " , temp_2)
Output:
Unique List 1 : [ 10 , 20 , 30 , 80 , 40 , 100 , 50 , 60 , 70 , 90 ] Unique List 2 : [ 10 , 20 , 30 , 80 , 40 , 100 , 50 , 60 , 70 , 90 ]
Here, tolist() function is used to convert the returned Numpy arrays to Python lists.
In the above example, we are importing the pandas module and giving it the name pd for further use in the source code. Now, in the first part of the program, we are accessing the unique(seq) function using the dot operator (.) and then converting its returned value to a list using tolist() function to get the required list.
In the second part, we are converting the input list into a Pandas Series (one-dimensional numpy array capable of holding data of any type) using the Series(seq) function. Then we use the dot operator (.) to apply the drop_duplicates() function to the resulting series. Finally, we are converting the result of the above-described statement to a list using the tolist() function.
Highlights:
(1) Pandas module provides functions such as unique() and drop_duplicates
(2) Both these functions preserve the order while removing duplicates.
(3) Pandas unique() function is faster than Numpy unique() function.
Method 10 : The reduce() Function
We can efficiently remove duplicates from a list using reduce() function provided by the functools module.
The reduce(function, sequence) method is used to cumulatively apply a particular function having two arguments to the elements of the sequence by:
- Traversing the sequence from Left to Right, and
- Applying the given function to the first two elements and storing the result, then
- Applying the same function to the previously stored result along with the next element in the sequence, and
- Repeating it until there are no elements left in the sequence.
Let's look at an example to understand how the reduce() function can be used to remove duplicates from a list:
Code:
# importing reduce function from functools module from functools import reduce # main list a = [ 10 , 20 , 10 , 20 , 20 , 30 , 30 , 10 , 80 , 40 , 100 , 50 , 60 , 70 , 80 , 90 , 40 , 60 , 90 , 10 ] # the initializer for the reduce function initializer = ( list (), set ()) def duplicate_removal ( temp, item ): # Check if the item is present in the list of the initializer tuple or not. if item not in temp[ 1 ]: # If the item is not present, i.e., it's a new occurrence. # Adding the unique elements to the list and the set of the initializer tuple temp[ 0 ].append(item) temp[ 1 ].add(item) # Returning the tuple - ([unique_list], {unique_set}) return temp # Removing duplicate elements using Reduce() function unique_list = reduce(duplicate_removal, a, initializer)[ 0 ] print ( "Unique List : " , unique_list)
Output:
Unique List : [ 10 , 20 , 30 , 80 , 40 , 100 , 50 , 60 , 70 , 90 ]
The reduce() function has an optional argument known as the initializer. If it is present in the function call, the reduce function will call the particular function with the value of the initializer and the first item of the sequence to perform the first partial computation. Then, it will cumulatively call the function with the partial computation and the next element in the sequence.
Here, we are providing a two-element tuple (containing a list and a set) as the initializer. Hence, at every step, a tuple is passed as an argument along with the items in the sequence to the duplicate_removal function. The items are added to the list and set in the tuple if they are not already present. Therefore, each new occurrence of an element in the original list is stored in an empty list, and the set acts as a look-up table for the reduce function.
The reduce() function is widely used to process iterables without writing Python for loops as the internal functionality of the reduce() function is written in C instead of Python, i.e., its internal loop is faster than that of explicit Python for-loop. Also, this method does not require extra space to store the unique elements. Hence, this is the most efficient way to remove duplicates from lists in Python.
Highlights:
(1) Most efficient method to remove duplicates.
(2) Uses reduce() function provided by the functools module.
NOTE:
Out of all the methods we have discussed, note that the Set Methods, the Dict methods, and built-in functions require the elements in the list to be hashable, i.e., they should be immutable (non-changeable). If the elements of the list are mutable such as lists or dictionaries, it is advisable to use the naive method for duplicates removal.
Conclusion
- Duplicates present in a list can be removed using: Sets, Built-in functions, or Iterative methods.
- If the elements present in the list are non-hashable, always use an iterative approach, i.e., traverse the list and extract unique items. Iterative approaches include the Naive Method, List comprehensions, and List.count() methods.
- If the order of the elements is not so important, then we can use the Set method and the Numpy unique() function to remove duplicates.
- For preserving the order of elements, we can use Pandas functions, OrderedDict, reduce() function, Set + sort() method, and the Iterative approaches.
Read More
- Sets in Python
Source: https://www.scaler.com/topics/remove-duplicates-from-list-python/
0 Response to "Python Use Continue to Remove Duplicates"
Post a Comment